pythonで複数サイトをwebスクレイピング

今回はpythonでwebスクレイピングによって複数のサイトから特定の情報を取得した後、その情報をメール送信するという処理を行います。
「webスクレイピング」
webスクレイピング(以下、スクレイピング)とは、webサイトのhtmlからプログラムを使って自動的に情報を抽出、整形することです。定期に特定のサイトを複数閲覧する場合、自動的に情報を取得できるようにすれば非常に効率的です。
今回はpythonでスクレイピングした後、取得したデータをメールで送信する所まで行います。ムスリムの知人の依頼もあって、礼拝時間・国際ニュース・某出版社のブログの情報を取得するプログラム(get_information.py)を実装してみました。
実装したプログラムはGithubで公開しています。
★開発環境
OS → Windows10
pythonのversion → 3.7.0
エディタ → Visual Studio Code
ブラウザ → chrome
★全ソースコード
「BeautifulSoupを使ったスクレイピング」
pip install beautifulsoup4
次に本プログラム(get_information.py)実行に必要なモジュールをimportします。
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
import re
import lxml.html
import requests
import smtplib
from io import StringIO
from email import message
BeautifulSoupに他、スクレイピングに必要な urlibパッケージのrequestモジュールやlxmlモジュールもimportします。
また、今回はメールも送信するので、メール送信に必要なsmtplibモジュールとemail.mine.textモジュールもimportします。
次に礼拝時間を取得できるwebサイトへアクセスします。
今回はIslamicFinder(https://www.islamicfinder.org/)というサイトを参照しました。
このサイトを開いた後、F12を押して開発ツール画面を開きます。すると・・・

赤い丸で囲った箇所「span class="TodayPrayerTime"」に「04:36 AM」や「05:58 AM」と今日の礼拝時間が書いてあります。よって、span要素のclass属性が"TodayPrayerTime"の箇所を探す必要があります。
礼拝時間を取得するプログラムは以下の通りになります。
def do_pray_time():
#ここでwebサイトのhtmlを読み込む
islamic_soup = BeautifulSoup(islamic_finder, 'html.parser')
#各礼拝時間の名称を配列に格納
pray_name = [u"FAJR", u"SUNRISE", u"DHUHR",
u"ASR", u"MAGHRIB", u"ISHA", u"QIYAM"]
#読み込んだhtmlのh1属性の文字列(サイトの見出しに該当)を取得
pray_header = "//////Today Pray Time//////" + islamic_soup.h1.string + "\n"
pray_time = pray_header
#span要素のclass属性が"todayPrayerTime"の全てを取得
for i, span_element in enumerate(islamic_soup.findAll("span", class_="todayPrayerTime")):
if(span_element != None):
#取得したspan要素の文字列(礼拝時間)を取得
pray_time = pray_time + \
pray_name[i] + " " + span_element.text + "\n"
pray_time = pray_time + "\n\n\n"
return pray_time
次に国際ニュースからニュース別ランキングを取得するプログラムを実装します。
今回はイランの国際ニュースの『ParsToday』(http://parstoday.com/ja)の日本語サイトより情報を取得しました。ここにアクセスして、F12で開発ツールを開きますと…

太い赤丸で囲んだ、「アクセスランキング」が取得したい箇所です。一方、開発ツールの箇所をもう少し拡大してみますと、
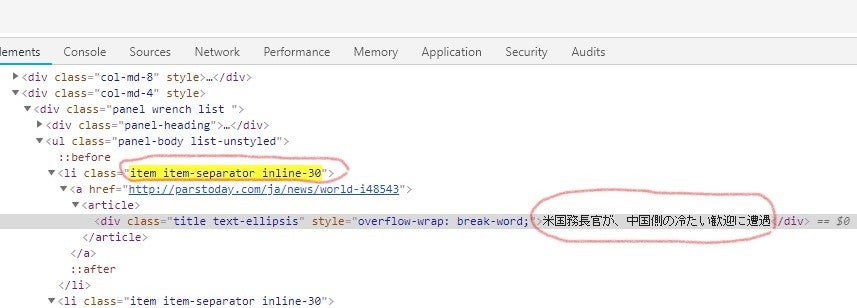
li要素の「class="item item-separator inline-30"」の中にあるdiv要素にアクセスランキング別のニュースのタイトル(ここでは「米国務長官が、中国側の冷たい歓迎に遭遇」)が記述されていることがわかります。よって、プログラムでもli要素のclass属性で値が"item item-separator inline-30"の中にあるdiv要素を参照します。
ニュースサイトよりアクセスランキングを取得するプログラムは以下の通りになります。
# Iran international news site
def do_iran_news():
#ニュースサイトのhtmlを取得
iran_international_soup = BeautifulSoup(res, 'html.parser')
iran_news_header = '*** Iran international new site ***' + \
"\n" + "News ParsToday" + "\n\n"
iran_news = iran_news_header
#li要素のclass属性で値が"item item-separator inline-30"の箇所を参照、その全てを取得
for i, li_element in enumerate(iran_international_soup.findAll("li", class_="item item-separator inline-30")):
#"item item-separator inline-30"の中のdiv要素及びa属性を参照
div = li_element.find("div")
a = li_element.find("a")
if(div != None):
#「div.text」で、ニュースランキングのタイトルを、「a.get("href")」で各ニュースへのリンクを取得
iran_news = iran_news + \
str(i+1) + "位" + " " + div.text + "\n" + a.get("href") + "\n\n"
iran_news = iran_news + "\n\n\n"
return iran_news
最後に出版社からのブログから情報を取得するプログラムを実装します。
今回は『鹿砦社トップページ』(https://www.rokusaisha.com/index.php)を参照しました。
このサイトを開きますと
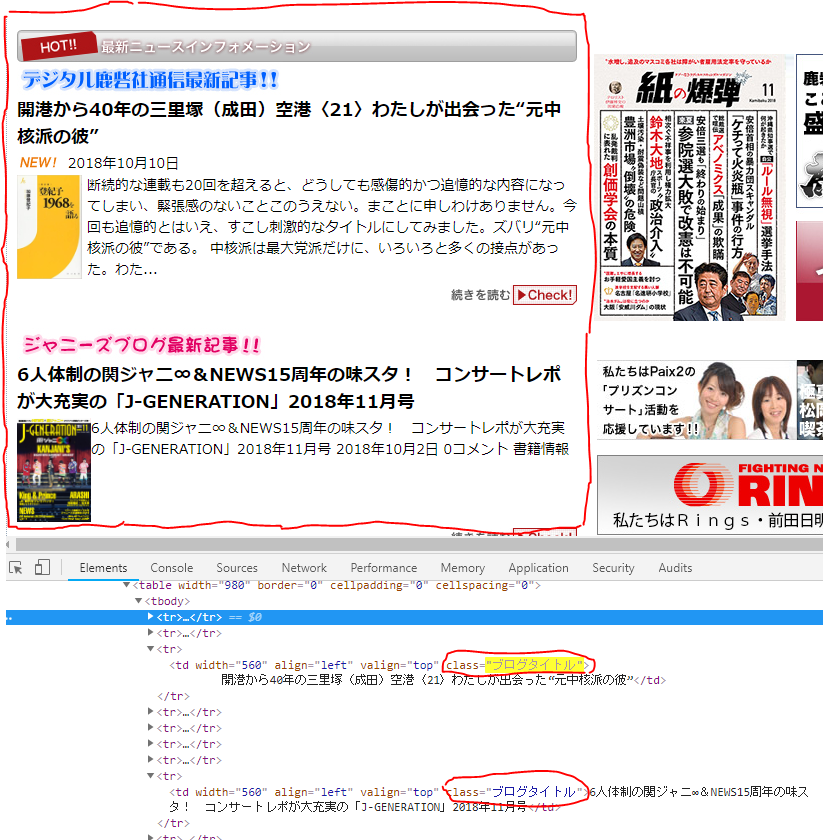
赤い四角で囲った箇所が新着ブログの情報で取得したい箇所です。
開発ツールでみると、td要素の「class="ブログタイトル"」に新着ブログのタイトルが記述されています。
したがって、新着ブログのタイトルを取得するプログラムは以下の通りになります。
# rokusaisha blog
def do_rokusaisha():
#ブログのhtmlを取得
rokusaisha_soup = BeautifulSoup(res2, 'html.parser')
rokusaisha_header = "********" + rokusaisha_soup.title.string + \
"********" + "\n" + "最新ブログ情報" + "\n\n"
rokusaisha = rokusaisha_header
#td要素のclass属性で値が"ブログタイトル"の箇所を参照、その全てを取得
for i, td_element in enumerate(rokusaisha_soup.findAll("td", class_="ブログタイトル")):
if(td_element != None):
#td要素のテキスト(新着ブログのタイトル)を取得
rokusaisha = rokusaisha + td_element.text + \
return rokusaisha
最後にこれまで説明した各関数(do_pray_time(), do_iran_news(), do_rokusaisha())で取得した情報をまとめてメールで送信します。ダミーのGmailアカウントにログインして、Gmailのサーバーを利用して、メールを送信します。
プログラムは以下の通りになります。
#send mail
def do_mail(information1, information2, information3):
# メールの内容を作成
all_information = information1 + information2 + information3
msg = message.EmailMessage()
msg.set_content(all_information) # メールの本文
msg['Subject'] = 'Today information''' # 件名
msg['From'] = from_email # メール送信元
print("Running")
server.ehlo()
server.starttls()
server.ehlo()
server.login(username, password)
server.send_message(msg)
server.quit()
print('Sending mail is completed')
最後に以下のプログラムを実行して、スクレイピングおよびメール送信は完了です。
if __name__ == '__main__':
do_mail(do_pray_time(), do_iran_news(), do_rokusaisha())
なお、Google側でセキュリティが起動するのでエラーが返ってくることもあります。 そこで、Google アカウントの「ログインとセキュリティ」で「安全性の低いアプリの許可」を「有効」にしておきましょう。セキュリティの都合上、プログラム実行時のみ有効にして、常時は「無効」にしておきましょう。手順は以下の画像の通りです。
自分のGoogle アカウントのログイン後、

画面右上の「Google アカウント」を選択して、

「ログインとセキュリティ」を選択。そして、

「安全性の低いアプリの許可」を有効にする。
実行すると以下のような内容のメールが、宛先宛先アドレスに送られます(ニュースやブログのタイトルはプログラムの実行日によって変わります)。
ー実行結果ー
//////Today Pray Time//////
Prayer Times in Kyoto
FAJR 04:36 AM
SUNRISE 05:59 AM
DHUHR 11:44 AM
ASR 02:59 PM
MAGHRIB 05:28 PM
ISHA 06:47 PM
QIYAM 12:52 AM
*** Iran international new site ***
News ParsToday
1位 世界が、ヘイリー国連大使の辞任を歓迎
http://parstoday.com/ja/news/w
2位 日本、韓国海軍の観艦式に不参加
http://parstoday.com/ja/news/j
3位 米大統領、サウジアラビアにアメリカの支持の見返りを要求
http://parstoday.com/ja/news/w
4位 トルコの報道各社、カショギ氏の事件関与が疑われるサウジアラビ
http://parstoday.com/ja/news/m
5位 日本がロヒンギャ族に関する正確な調査を求める
http://parstoday.com/ja/news/j
6位 アメリカにへつらうサウジ皇太子の風刺画
http://parstoday.com/ja/news/m
7位 アメリカ国連大使が辞任表明
http://parstoday.com/ja/news/w
8位 ロシア、中国、北朝鮮が、北朝鮮制裁の見直しを要求
http://parstoday.com/ja/news/w
9位 ニューヨークタイムズ、「サウジアラビア反政府ジャーナリストは
http://parstoday.com/ja/news/m
10位 イギリスで、自殺予防担当大臣が任命
http://parstoday.com/ja/news/w
********鹿砦社トップページ********
最新ブログ情報
カルト取材専門家が見る「しばき隊」の問題とは?「やや日刊カル
http://www.rokusaisha.com/blog
まさに“Yummy!!”な1冊! Kis-My-Ft2初の5大ドームツアーを収めた『Kis-M
http://www.rokusaisha.com/blog
終わりに
今回、比較的スムーズに実装できましたがサイトによっては要素の文字列を取得しにくいものもあります。今度はPDFファイルなどから情報を抽出するようなプログラムを組めればなと思います。
